Привіт усім.
Сьогодні поділюсь з вами одним цікавим методом або ж алгоритмом, який попався мені під час того, як Я вчився своєму Ремеслу. Цей метод відноситься до проблеми обчислення кількості входжень певних (або усіх) символів в рядку цих самих символів. Тобто, скільки разів кожна окрема буква алфавіту, попадається в цілому масиві цих букв.
Давайте спочатку, для простоти, переглянемо задачу на обрахунок однієї букви з довільного масиву. І які методи ми тут можемо використати? Очевидним рішенням буде, звичайно, використання алгоритму лінійного пошуку без інваріанти, оскільки нам необхідно обчислити усі входження однієї букви в масиві, а не найпершого її примірника. Тобто:
- ми спочатку створюємо масив довільного вмісту;
- після цього визначаємо, кількість входжень якого саме символу нам необхідно обрахувати;
- описуємо цикл, в якому маємо індексну змінну в якості ітератора для масиву (точніше для його перебору) і, власне головне, змінну, яка буде містити в собі значення кількості входжень.
Програма, за поданим вище планом, може виглядати наступним чином:
#include <iostream> /* ввід/вивід */
#include <string.h> /* функція strlen */
using namespace std ; /* щоб не писати "std::" */
/* неповторна і єдина */
int main (int argc, char** argv)
{
/* оголошуємо і ініціалізовуємо масив символів */
const char* Array = "I love programming" ;
/* оголошуємо ітератор і обрахункову змінну */
unsigned int iter, /* ітератор */
cscount ; /* змінна, у якій буде міститись значення кількості */
/* змінна в якій міститься буква (її ASCII код) */
/* кількість якої ми бажаємо обчислити */
/* її можна зчитувати і за допомогою об'єкта cin або функції scanf */
char cs = 'g' ;
/* основна магія тут */
for (iter=0, cscount=0; /* ініціалізовуємо усі змінні в нульове значення */
iter<strlen(Array); /* умова "охорони" циклу (не виходимо за межі масиву) */
++iter) /* з кожним кроком інкрементуємо значення ітератора */
{
/* перевіряємо, чи поточне значення масиву (код символу)
** співпадає з бажаним */
if (Array[iter]==cs)
{
/* якщо так - додаємо одиницю до обрахункової змінної */
++ cscount ;
}
/* якщо ні - нічого не робимо */
}
/* виводимо кількість на екран */
cout << "Count of char '" << cs << "' in string \""
<< Array << "\" is: " << cscount << endl ;
/* завершуємо виконання програми */
return 0 ;
}
Після компілювання і виконання даної програми, ми можемо побачити на екрані наступне (в даному випадку вищенаведений код знаходиться у файлі "single_char_count.cxx", компілятором являється GCC g++, а вихідний виконуваний файл ми називаємо "file"):
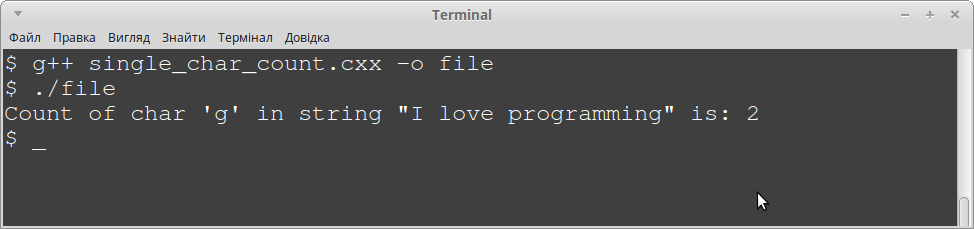
Обрахунок усіх символів
Тепер перейдемо до цікавішого методу, який можна використовується для обчислення усіх символів в масиві (замість масиву, Ви також можете використовувати об'єкт класу std::string). Він базується в наступному:
- виконуємо практично усі підготовлювані дії з попереднього прикладу;
- але в якості системи обрахунку кожної букви, ми будемо використовувати масив потужністю 256 значень (для усіх можливих ASCII символів), а в якості індексів даного масиву - значення кодів символів (символи в пам'яті зберігаються в якості чисел) з масиву.
Розглянемо програму, яка реалізовує даний метод.
#include <iostream> /* ввід/вивід */
#include <string.h> /* функція strlen */
using namespace std ; /* щоб не писати "std::" */
const unsigned int Alenght = 256 ;
/* неповторна і єдина */
int main (int argc, char** argv)
{
/* оголошуємо і ініціалізовуємо масив символів */
const char* Array = "I love programming" ;
/* оголошуємо ітератор і обрахункову змінну */
unsigned int iter; /* ітератор */
/* змінна-масив для зберігання значень кількостей */
unsigned int Ccounts [Alenght] ;
/* ініціалізовуємо усю пам'ять в значення нуля */
memset (&Ccounts, 0, Alenght*sizeof(unsigned int)) ;
/* основна магія тут */
for (iter=0; /* ініціалізовуємо ітератор в нульове значення */
iter<strlen(Array); /* умова "охорони" циклу (не виходимо за межі масиву) */
++iter) /* з кожним кроком інкрементуємо значення ітератора */
{
/* збільшуємо значення елемента масиву Ccounts на одиницю
** за значенням коду символу елемента масиву Array
** в якості індексу масиву Ccounts */
++ Ccounts [ Array[iter] ] ;
}
/* виводимо кількість на екран */
for (iter=0; iter<Alenght; ++iter)
{
/* перевіряємо, чи значення елементу не нульове
** (ми ж не бажаємо бачити повідомлення про нульове входження
** символу, яких більшість з 256 значень) */
if (Ccounts[iter]>0)
{
cout << "symbol '" << (char)iter << "' has "
<< Ccounts[iter] << " occurences" << endl ;
}
}
/* завершуємо виконання програми */
return 0 ;
}
Компілюємо її своїм улюбленим компілятором (у мене це GCC), виконуємо її у терміналі (файл з кодом називається "all_char_count.cxx") і бачимо наступну картину:
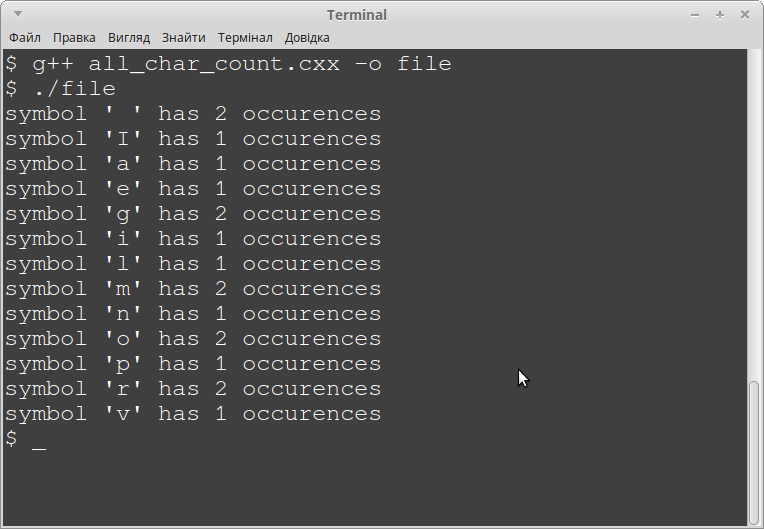 Найпершим ми бачимо символ пробілу з кодом 32 (в шістнадцятковій 0x20), після нього будуть йти усі великі літери алфавіту (в нашому випадку це англійська літера 'I') і в подальшому усі символи малого регістру, які мають найбільші коди (в нашому випадку значення кодів знаходиться між 0x61 для 'a', і 0x76 для 'v' в шістнадцятковій системі числення).
Найпершим ми бачимо символ пробілу з кодом 32 (в шістнадцятковій 0x20), після нього будуть йти усі великі літери алфавіту (в нашому випадку це англійська літера 'I') і в подальшому усі символи малого регістру, які мають найбільші коди (в нашому випадку значення кодів знаходиться між 0x61 для 'a', і 0x76 для 'v' в шістнадцятковій системі числення).
Проблема
Проблема в даному методі полягає саме в кодуванні символів. А дане кодування символів, себто коди ASCII не задовільняють наші потреби в обрахуванні кількості символів Української абетки, хіба-що Ви використовуєте кодування KOI8-U. Моя ОС використовує кодування UTF-8, тому Я не можу використовувати стандартний тип "char", який вміщує один байт даних. Для обчислення символів при використанні кодування UTF-8 (взагалі-то UTF-8 це не система кодування символів, а лише представлення стандарту UNICODE, про що Я напишу пізніше) нам необхідно використовувати спеціальний тип wchar_t, який вміщує в Unix-подібних ОС 4 байти (необхідних для UTF-8), а у ОС сімейства Windows, яка використовує UTF-16 для таких цілей, 2 байти.
Ще однією проблемою в даному методі, являється пам'ять. Для обрахунку символів ASCII потрібно всього 256 значень (потужність типу "char" - 1 байт = 28 значень), на що ми можемо закрити очі в даному випадку. Але ми вже не можемо ігнорувати кількість елементів для обрахунку усіх можливих значень з проміжку у 4 байти. Тобто, для того щоб обрахувати кількість символів з рядка UNICODE, нам знадобиться 232=4 294 967 296 елементів масиву, кожен з яких повинен мати 4 байти (це в межах даного методу).
Рішення
Вирішенням вищенаведених проблем буде використання типу "wchar_t" і такого чудового контейнера з бібліотеки STL, як "map". Даним контейнером бібліотеки STL, ми реалізовуємо ідею економії пам'яті, яка полягає у тому, що її виділення відбувається тільки за необхідності. Тобто віртуально, ми маємо в пам'яті усю множину елементів, але по-факту, у нас виділені тільки необхідні. В найгіршому випадку, великий текст тільки Українськими символами може потребувати 33 елементи для самих символів плюс з десяток елементів для символів пунктуації (і можливо десяток елементів для цифр).
"map" - це асоціативний список. Кожен елемент даного списку містить два значення: first - це ключ до елемента і "second" - для самого значення елементу. Map являється шаблонним контейнером, отже обидва значення (ключ і його "асоціація") можуть мати довільний тип (число, рядок, буква, користувацький тип і т.д.). Вставка нових елементів в контейнер відбувається за константний час, оскільки він реалізований за допомогою зв'язаного списку (ітератори даного типу не підтримують операції "<" і ">"). Усі елементи об'єкта "map" зберігаються в сортованому порядку, що дозволяє швидко знаходити необхідні.
Вищенаведена програма з використанням об'єкта "map" може виглядати наступним чином:
#include <iostream> /* ввід/вивід */
#include <string> /* wstring */
#include <map> /* ! */
using namespace std ; /* щоб не писати "std::" */
/* неповторна і єдина */
int main (int argc, char** argv)
{
/* оголошуємо і ініціалізовуємо масив символів */
//const wchar_t* Array = L"Я обожнюю програмування!" ;
wstring Array = L"Я обожнюю програмування!" ;
/* оголошуємо ітератор і обрахункову змінну */
unsigned int iter; /* ітератор */
/* змінна-масив для зберігання значень кількостей */
map<wchar_t, unsigned int> Ccounts ;
/* основна магія тут */
for (iter=0; /* ініціалізовуємо ітератор в нульове значення */
iter<Array.size(); /* умова "охорони" циклу (не виходимо за межі масиву) */
++iter) /* з кожним кроком інкрементуємо значення ітератора */
{
/* збільшуємо значення елемента масиву Ccounts на одиницю
** за значенням коду символу елемента масиву Array
** в якості індексу масиву Ccounts */
++ Ccounts [ Array[iter] ] ;
/* оператор "[]" автоматично додає в список елемент
** якщо такого ще не існує */
}
/* виводимо кількість на екран */
/* спеціальний внутрішній тип ітераторів для map */
map<wchar_t, unsigned int>::iterator jter ;
/* цикл виведення результатів */
for (jter=Ccounts.begin(); jter!=Ccounts.end(); ++jter)
{
cout << "symbol '" << (*jter).first << "' " << " has "
<< (*jter).second << " occurences" << endl ;
}
/* завершуємо виконання програми */
return 0 ;
}
Після виконання програми, ми можемо побачити наступне:
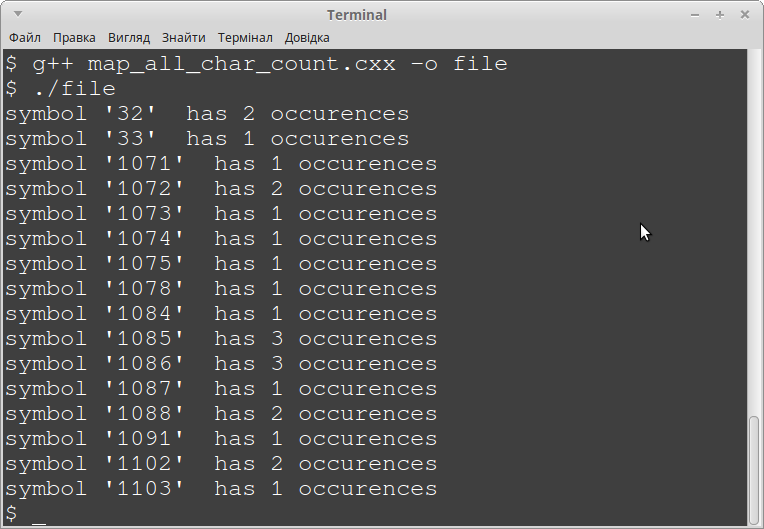 В даній програмі ми також використовуємо спеціальний клас wstring - це такий ж тип, як і string, але для використання разом з "wchar_t". На жаль, побачити які саме букві відповідає кількість неможливо, оскільки необхідно мати функції перетворення символів з UTF-16 у, зрозумілу терміналу, UTF-8, написання яких виходить за межі даної статті (Рядок "Я обожнюю програмування" автоматично перетворюється компілятором з кодування UTF-8 файлу коду у UTF-16 завдяки лідируючій букві "L" перед відкривання символу подвійних лапок, без якої змінна-об'єкт Array буде містити спотворені дані). Але ми можемо побачити, що символу пробіла (код 32 десяткове) відповідає два входження, знаку оклику (код 33 десяткове) - одне, далі йдуть коди букв в порядку зростання: для 'а' (код 1071 десяткове) одне входження, для 'б' (код 1072 десяткове) - два і т.д.
В загальному, передостанній і останній методи використовують хеш-таблиці.
В даній програмі ми також використовуємо спеціальний клас wstring - це такий ж тип, як і string, але для використання разом з "wchar_t". На жаль, побачити які саме букві відповідає кількість неможливо, оскільки необхідно мати функції перетворення символів з UTF-16 у, зрозумілу терміналу, UTF-8, написання яких виходить за межі даної статті (Рядок "Я обожнюю програмування" автоматично перетворюється компілятором з кодування UTF-8 файлу коду у UTF-16 завдяки лідируючій букві "L" перед відкривання символу подвійних лапок, без якої змінна-об'єкт Array буде містити спотворені дані). Але ми можемо побачити, що символу пробіла (код 32 десяткове) відповідає два входження, знаку оклику (код 33 десяткове) - одне, далі йдуть коди букв в порядку зростання: для 'а' (код 1071 десяткове) одне входження, для 'б' (код 1072 десяткове) - два і т.д.
В загальному, передостанній і останній методи використовують хеш-таблиці.