Шаблонний клас std::collate відноситься до стандартних facet-об'єктів локалі, і призначений для порівняння рядків у специфічній до необхідної локалі манері. Оголошення даного класу виглядає наступним чином:
template <class charT> class collate ;
Параметр шаблону charT вказує на тип комірок, які безпосередньо зберігають символи у певному кодуванні.
Сам клас collate містить захищений деструктор - програми повинні створювати примірники тільки дочірніх класів від даного.
Усі стандартні об'єкти класу std::locale підтримують наступний мінімальний набір ініційованих об'єктів класу collate:
- collate<char> - звичайні символи;
- collate<wchar_t> - розширений тип символів.
Нутрощі класу
Методи
explicit collate (size_t refs=0) ;
Конструює facet-об'єкт класу collate.
int compare (const char_type* low1,
const char_type* high1
const char_type* low2,
const char_type* high2)
const ;
Порівнює послідовності символів у проміжку [low1, high1) з послідовністю [low2, high2), повертаючи 1, коли перша послідовність вважається більшою ніж друга, або -1, якщо вона вважається меншою за другу. В іншому випадку, коли послідовності рівні, метод повертає нуль.
Даний метод викликає віртуальний захищений метод do_compare, який за умовчанням виконує лексикографічне порівняння, і який реалізований у дочірніх класах collate.
string_type transform (const char_type* low, const char_type* high) const ;
Перетворює і повертає об'єкт рядкового типу (string, wstring) символи якого являються такими, що під час лексикографічного порівняння з значеннями символів, які також повернуті даним методом, метод std::collate::compare повертає той самий результат, що і з звичайними символьними послідовностями.
Це дозволяє пришвидшити процес порівняння коли один рядок потребує порівняння з багатьма іншими рядками, оскільки алгоритми лексикографічного порівняння (на подобі lexicographical_compare) може бути набагато швидшим ніж std::collate::compare.
Даний метод являється делегатом - викликає метод do_transform, який реалізовується дочірніми класами std::collate. В класичній локалі даний метод просто повертає рядок з не зміненими значеннями.
long hash (const char_type* low, const char_type* high) const ;
Повертає хеш-значення, яке представляє послідовність символів [low,high).
Хеш-значення являється таким, що два різних послідовностей символів з однаковими хеш-значеннями, результують у значення нуль при порівнянні методом std::collate::compare.
Зверніть увагу, що не гарантується, що хеш-значення будуть мати унікальні значення. Тобто два послідовності символів можуть отримати одинакові хеш-значення.
Даний метод являється делегатом - тобто викликає віртуальний захищений метод do_hash, який реалізовується у потомках класу collate.
Вбудовані типи
typedef CharT char_type ;
Тип комірок, які зберігають закодовані символи.
typedef basic_string<CharT> string_type ;
Тип рядкових об’єктів у відповідності до типу символів.
Приклади
Приклад #1
Розглянемо простий приклад використання facet-об'єкта локалі для порівняння двох рядків методом collate::compare.
#include <locale> /* усе корисне разом з collate */
#include <iostream> /* cout wcout */
using namespace std ;
/* головна функція програми */
int main (int argc, char** argv)
{
/* створюємо піддослідну локаль */
locale lpreferred ("") ;
/* створюємо піддослідні рядки символів */
const wchar_t s1p[] = L"Козак" ;
const wchar_t s2p[] = L"Кобзар" ;
/* дізнаємось довжини рядків символів */
int s1pL = sizeof(s1p)/sizeof(s1p[0]) ;
int s2pL = sizeof(s2p)/sizeof(s2p[0]) ;
/* перевіряємо наявність facet-об'єкта collate
** у локалі, якщо його немає - завершуємо програму */
if (!has_facet < collate<wchar_t> > (lpreferred))
{
/* повідоалення на українській може неправильно
** відображатись у терміналі, якщо він не підтримує UTF-8 */
cout << "Локаль немає об'єкта std::collate<wchar_t>." << endl ;
return 0 ;
}
/* Отримуємо facet-об'єкт collate<wchar_t> з локалі lpreferred.
** Дана функція може генерувати виключення. */
const collate<wchar_t>& clfacet = use_facet < collate<wchar_t> > (lpreferred) ;
/* порівнюємо два рядки символів */
int result = clfacet.compare (s1p, s1p+s1pL,
s2p, s2p+s2pL) ;
/* Викликаємо функцію і виводимо відповідне повідомлення */
cout << "Результат функції порівняння: перший рядок s1p стоїть "
<< (result>0 ? "після " : (result<0 ? "перед " : "разом"))
<< "s2p." << endl ;
return 0 ;
}
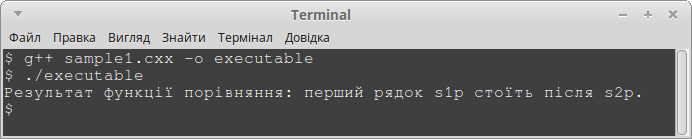
Вивід програми:
Приклад #2
Розглянемо приклад отримання хеш-значень рядків з попереднього прикладу.
#include <locale> /* усе корисне разом з collate */
#include <iostream> /* cout wcout */
using namespace std ;
/* головна функція програми */
int main (int argc, char** argv)
{
/* створюємо піддослідну локаль */
locale lpreferred ("") ;
/* створюємо піддослідні рядки символів */
const wchar_t s1p[] = L"Козак" ;
const wchar_t s2p[] = L"Кобзар" ;
/* дізнаємось довжини рядків символів */
int s1pL = sizeof(s1p)/sizeof(s1p[0]) ;
int s2pL = sizeof(s2p)/sizeof(s2p[0]) ;
/* перевіряємо наявність facet-об'єкта collate
** у локалі, якщо його немає - завершуємо програму */
if (!has_facet < collate<wchar_t> > (lpreferred))
{
/* повідоалення на українській може неправильно
** відображатись у терміналі, якщо він не підтримує UTF-8 */
cout << "Локаль немає об'єкта std::collate<wchar_t>." << endl ;
return 0 ;
}
/* Отримуємо facet-об'єкт collate<wchar_t> з локалі lpreferred.
** Дана функція може генерувати виключення. */
const collate<wchar_t>& clfacet = use_facet < collate<wchar_t> > (lpreferred) ;
/* визначаємо хеші рядків */
long s1hash = clfacet.hash (s1p, s1p+s1pL) ;
long s2hash = clfacet.hash (s2p, s2p+s2pL) ;
/* Викликаємо функцію і виводимо відповідне повідомлення */
cout << "Хеш-значення 1 рядка: " << s1hash << endl
<< "Хеш-значення 2 рядка: " << s2hash << endl ;
return 0 ;
}
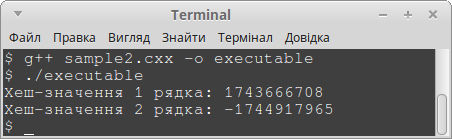
Вивід програми наступний: